Opera mini
August 12, 2006 | Comments OffWhen I find myself stuck in a boring place (like the DMV) I turn to my last hope for mindless entertainment: my cell phone. Up until recently I had very limited options. Backgammon was enough to entertain me for at least 10 minutes, but it was starting to get old. Surfing the web via GPRS with the built in WAP browser was mildly entertaining; I used to have a few trivia games bookmarked but they’re now defunct. A couple of weeks ago I read about Opera Mini and just this week I got to try it out. It is amazingly good for a 64kb program. As a point of reference, on my XP system notepad.exe is 68kb. And thanks go the mobile edition of Google Reader, I can keep up with my reading. It doesn’t support javascript or DHTML but one can hardly hold that against it. The UI took some getting used to but that’s likely because I was used to the built in WAP browser. If you have a phone that lacks a decent browser and supports MIDP 1.0 or higher take advantage.
More PSA to Lightroom details
August 4, 2006 | 4 CommentsI posted a link to my results to the Adobe Lightroom Beta forums and someone asked for additional details, and I realize I skimped on the technical stuff a little too much. Here are the details on the steps as described in the previous post. I got a lot of information out of people doing a similar thing: transferring PSA data into iMatch.
Continue reading More PSA to Lightroom details…
Lightroom Import Success
August 4, 2006 | Comments Off Update: I posted excruciating detail in the following post.
Update: I posted excruciating detail in the following post.
I was able to successfully migrate my PSA tag associations to Lightroom. In terms of working time I probably spent about 3 or 4 hours working on it (highly interrupted). The process more or less broke down like thie:
- Import the images into Lightroom
- Use PSATool to dump PSA catalog to text file
- Build keyword list from psa dumpfile
- Import keyword list into Lightroom
- Update the SQLite database to add the mappings
I could be a lot more turn key. It could be as simple as steps 2 and 5, but I wanted to manipulate the database directly as little as possible for my first attempt. There’s columns whose purpose is not entirely obvious to me and I’d just as well let Lightroom create most of the entries than do it myself. This way the only table we are manipulating directly is AgLibraryTagImage (the image < -> tag mappings), and this table is fairly simple. Likewise the AgLibraryTag table is easy to manipulate, but importing the keywords is the easiest step of the process (and there’s magic with the keyword lists it builds). Importing the files into Lightroom took a very long time (I’d guess 2-3 hours). And I only have about 5000+ images, some of the requesters on the Adobe boards had upwards of 15000. There is a lot of magic going on populating the Adobe_images and Adobe_imageFiles tables (mostly metadata caching).
I actually had written this post on Sunday night, thinking I had completed my task, but after I wrote this the import finished and it actually didn’t work. I thought I had missed some nuance of the schema but as it turns out, it was just a subtle bug in the import process. However, this led me to discover an reference that I hadn’t previously considered. To the side is a screenshot of my successful import.
Lightroom Follow-Up
July 28, 2006 | Comments Off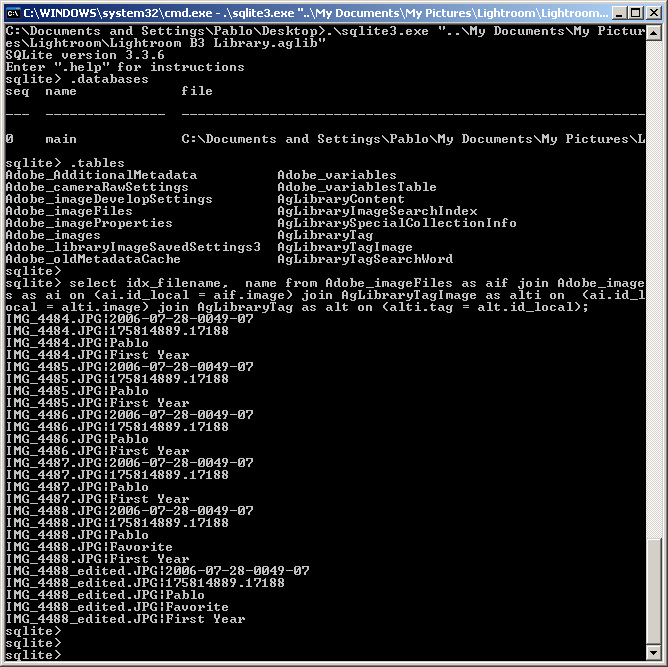 This is probably the first time I’ve ever posted twice in one day, so I think my excitement about Lightroom shows. In the introductory video on the Adobe Labs site the demonstrator mentions that Lightroom’s backend is a relational database, I figured (based on the PSA history) that he was referring to MS Access. Then as I was digging around reading release notes, at the bottom there is a copyright notice for SQLite. So I downloaded the SQLite command line utility and sure enough the “preferences” files are SQLite databases. Here’s a screenshot of me doing some joins to get the image < -> tag relationships.
This is probably the first time I’ve ever posted twice in one day, so I think my excitement about Lightroom shows. In the introductory video on the Adobe Labs site the demonstrator mentions that Lightroom’s backend is a relational database, I figured (based on the PSA history) that he was referring to MS Access. Then as I was digging around reading release notes, at the bottom there is a copyright notice for SQLite. So I downloaded the SQLite command line utility and sure enough the “preferences” files are SQLite databases. Here’s a screenshot of me doing some joins to get the image < -> tag relationships.
There is also a copyright notice for Lua in the release notes. It’s really encouraging to see large companies starting to take advantage of open source/public domain software in their commercial products. As a company they win by saving development time and using tested software. As a user I win because I (theoretically) get the software cheaper as a result and I’m not locked in.
Photoshop Album and Lightroom
July 28, 2006 | Comments OffA posting on Sree Kotay‘s blog alerted me to a product I had never heard of: Adobe Lightroom, and look!, a free beta. I’ve been using Adobe Photoshop Album (aka, PSA) for years now and it’s nice and all, but noticeably outdated and semi-abandoned. I watched the video on their site and decided that it was something that really appealed to me. It’s fairly slick and a little clumsy on my desktop. I only imported 6 images into it and it was using 250mb of memory (finally, a worthy memory hog worthy of competing with Firefox!). It is beta so maybe the memory footprint will shrink, but I really like it so far. One thing that appeals to me is that it doesn’t modify the underlying image. It *feels* like when you make a modification it applies it as a filter over the original image (non-destructive editing). I actually don’t mind PSA’s way of doing this; it makes a copy of the image called IMAGENAME_edited.jpg, but the Lightroom way seems to have some advantages. The in-program editing is really good, mostly obviating the need to take it into GIMP or Photoshop to do edits.
One feature that’s missing is importing from PSA (or heck, *anything*). I checked the feature request forum and fortunately I’m not the only heavy PSA user, there are many clamoring for an import feature. The most important data is the tags/labels associated with the images. This got me worried: was I stuck with PSA? Would the Anna graduate highschool while I’m still using software from 2002 to catalog her pictures? I started to search to see if I anyone had bothered to import PSA catalogs into their software. Along the way I found sweet relief. The PSA catalog is merely an MS Access database! Just to confirm, I made a copy of my catalog named test.mdb, and it opened right up in Access. Whew, dodged a bullet. I’ll just need to figure out how to get the data into Lightroom, and at first glance, not sure how easy that will be.
Adjusting the WordPress thumbnail threshhold
July 17, 2006 | 2 CommentsLong title for a simple problem. If you are using WordPress and are annoyed that it won’t generate thumbnails for pictures larger than 3 megapixels, the place to change this is wp-admin/inline-uploading.php . The line in question reads (line 87 in my copy):
if ( $imagedata['width'] * $imagedata['height'] < 3 * 1024 * 1024 ) {
Change the 3 to 4 or 5 or what have you. You don’t want to go too crazy since there are some valid concerns about memory consumption and speed. PHP has some configuration for how much memory a script my use (“memory_limit” in my php.ini) so you might have to raise this as well. Currently I’m resizing 4 megapixel images with the default 8mb memory limit without any problems.
Google Reader
July 3, 2006 | Comments OffI might be more habitual than the average person – some friends even suggest I have some minor OCD – so I tend to get stuck in ruts with certain tools. It took me a long time to switch from Mozilla to Firefox (in fact, I still run it on the laptop and a workstation at work). For ages I was using Trillian as my RSS reader. It worked OK until I started following a lot of blogs and then it got unwieldly. About then I discovered Google Reader and I’ve been hooked ever since. And remember that entry about I *heart* Outlook, well I’m working on switching to Google Calendar. I even added my Reader starred items to the sidebar that you’ve probably hidden because it’s annoying. I wanted to express some interesting uses of these tools.
With calendar I intend for Leigha and I to have views of each other’s calendars. The interesting use will be adding her XML feeds to my Google Reader subscriptions, so I’ll be notified when she creates new events.
I have a label in my Reader configuration called “fast”. The idea is that only a couple of my feeds (Slashdot and MakeBlog) are high volume. All the others are fairly low traffic, so I want to read those first (especially if I have a few minutes before a meeting). The trick I learned today is using Firefox’s live bookmarks in conjuntion with my shared “fast”-labeled feed.
Some other things I’ve been wanting to get off my chest: Firefox’s memory leaking is completely annoying (I don’t think Mozilla ever got quite as large as Firefox seems to get). The other thing is that WordPress’s arbitrary decision to NOT thumbnail images greater than 3 megapixels is arbitrary, stupid, and not configurable. They seem to think this is not a problem. Finally, DilbertBlog is probably the funniest and most interesting subscription I have. I stay up late at nights just reading old posts.
Galleon fun
June 29, 2006 | 1 CommentHere’s a google oddity. Google for “galleon” , a few results down, it will give you results for “Galleon Tivo”. Not sure why it does that, since I haven’t seen similar results at any other point in time. I digress.
After I got the TiVo happily onto the lan, I resumed poking around with the TiVo HME stuff. On their site I found a link to Galleon as a very popular HME app. I downloaded it and was very impressed with it. It reads the iTunes data file in as a source for serving music (it has other modes, like reading raw directories). This provided a much simpler and more maintanable solution than the iTunes/TiVoServer proxy I had hacked together. It gives access to content I hadn’t been making available previously, such as podcasts. The UI for the galleon config leaves something to be desired, but isn’t too painful once you get the idea. Some of the apps I really like are the weather, the movie listings, and RSS reader.
If someone with some UI sense would give the config UI a good whack, I think it’d be a really compelling use of HME. I also found AudioFaucet interesting as well. I had to file some support requests because I couldn’t get it working right at first but Kyle was very quick answering my questions. I had moved my iTunes library and AudioFaucet expects to find it in the ‘MyMusic’ folder.
The Anna Show
June 5, 2006 | Comments OffThe grandparents want a way to “visit” with Anna. I was originally going to do it with a cheap webcam, but Leigha got me a nice digital camcorder for Christmas. So I figured, why not give them good quality video?
I consulted with my streaming video guru, Eric, and he suggested Windows Media Encoder. This caused about as much hesitation as you probably think. It turns out WME is free, and it’s freaking awesome. I also tried to toe the company line on this one. I wanted to use NSV to stream the video and I wanted the viewers to use WinAMP. I figured that’d be a nice, free, open-source way to get this accomplished. The problem is that not a whole many people are doing this, especially not using a windows desktop (there seemed to be *SOME* documentation for doing this on Linux). So after a few failed attempts with NSVCap/Icecast/Winamp, I decided to go with path of least resistance.
The only downside to the WME solution is that I’m limited to five connections/viewers. This is probably reasonably close to the amount of bandwidth I can push anyway. So anything above 5 viewers and I’ll need to find some Windows Media Server out there that’s willing to let me stream 30-60 minutes of live video to handful of people once a week.
If you haven’t played with WME, give it a shot. The UI is fairly good, but broadcasting is a fairly complex operation, so it’s pretty close to as good as it could be. If you play with it for a while, you’ll definately feel like you’re a hotshot live TV producer.
I *heart* Outlook
May 19, 2006 | Comments OffIn my quest to further degrade myself in the eyes of other technical people, I’ve decided to come clean: I love Outlook. Feel better? I don’t. As we proceeded into pregnancy, our schedules became less possible to handle by memory alone. Leigha kept a schedule on her desk but it wasn’t always complete and not very accessible when we weren’t home. A similar thing was occurring with our contact information. What we needed was a shared calendar, and Outlook seemed like the easiest way to go.
I definately didn’t want to be running an Exchange server at home, so first I looked at some synchronization options. There’s a good resource list at slipstick.com. I initially went with a free trial of OfficeCalendar. To be honest, it worked relatively well. It just wasn’t *great*. And there were some glitches and it required my desktop to be on. It just felt like a dirty hack (which it was).
The last resort (before actually running Exchange) was to look for Exchange-compatible servers. It turns out there are a couple. Zimbra had a lot of potential. It was very pretty, but the Outlook plugin was vaporware. I also tried some other solution (Samsumg Contact?) that was a really bad hackjob on HP Openmail. Finally I ended up with Scalix. Pros: Free Outlook plugin, runs on Linux, came with RPMs. Cons: Only supports RHEL 3/4, Fedora Core 4. These weren’t awful cons.
First I setup an RHEL AS4 box to play around with it, and it worked REALLY nicely. Eventually I got tired of having a whole computer just for Scalix so I managed to move it onto the Debian box with a lot of imaginative symlinking. That’s pretty much it: We run Outlook on the desktops; we have a shared calendar and contact folder; the permissions all work nicely; it has offline synchronization; we have web access remotely; it all runs on the Debian server.